En nuestra anterior entrada sobre redes neuronales (https://magiquo.com/redes-neuronales-o-el-arte-de-imitar-el-cerebro-humano) se recogía la definición que de estas hacía la Enciclopedia Británica. Esta institución las define como aquel programa informático que funciona inspirándose en las redes del cerebro para realizar funciones cognitivas como la resolución de problemas y el aprendizaje.
Señores: ¡el ojo artificial!
Una vez que estuvieron los conocimientos científicos sobre el funcionamiento del cerebro y tras la explosión de teorías acerca de la Inteligencia Artificial de los años 40, apareció el primer perceptrón.
Su creador fue Frank Rosenblatt, investigador del Laboratorio de la Universidad de Cornell en Ithaca (nuevaYork). El definió su invento como la unidad fundamental de una red neuronal. En ella, las entradas pasan a través de algunos «preprocesadores», que se denominan unidades de asociación. Estas unidades de asociación detectan la presencia de ciertas características específicas en las entradas. De hecho, como su nombre indica, un perceptrón estaba destinado a ser un dispositivo de reconocimiento de patrones ópticos binarios. Es decir, a emular el ojo humano.
La investigación en redes neuronales sufrió un parón de varios años, como en general todo el desarrollo de la IA. Desde los 80 han vuelto a la escena, momento desde el cual se han desarrollado varios tipos de redes según la funcionalidad a la que estén destinadas y su forma de funcionar. Uno de esos tipos es la red convolucional. Este tipo de herramienta se utiliza de forma masiva hoy en día, por ejemplo, para el reconocimiento de fotos, patrones visuales, incluso caras.
De hecho, es uno de los grandes desarrollos de la Inteligencia Artificial. El investigador Geoffrey Hinton, premio Turing 2019 (el óscar de la IA) afirma que las redes neuronales convolucionales reconocen imágenes con mayor precisión que cualquier otra técnica del momento.
Además, de ser un pieza fundamental en la comercialización de los futuros coches autónomos, este tipo de redes se están usando para estudiar y prevenir enfermedades. Por ejemplo, el Hospital Universitario de Canarias y la Universidad de La Laguna han hecho público recientemente un proyecto de investigación conjunto para prevenir enfermedades oftalmológicas con estas redes artificiales, de tal manera que “con procedimientos matemáticos automatizados se identificarán con mayor precisión patologías de retina y nervio óptico”, afirman. Incluso se investiga su uso para evitar insuficiencia cardíaca.
Red convolucional para identificar flores
Para explicar cómo se entrena una red convolucional y que se entienda dónde reside el secreto de su éxito, en magiquo hemos decidido crear una y contar cómo lo hemos hecho paso a paso. “Una red neuronal clásica, es decir densa, mira una imagen como si fuera un vector plano. Es bueno para detectar muy bien una característica en un punto, pero tiene un problema para hacer reconocimiento. Si lo que ha identificado se mueve en el espacio no es capaz de detectarlo. La red convolucional tiene en cuenta la estructura espacial de los datos, la posición del objeto que ve; entiende que es lo mismo encontrar unas características en el punto cero, en el uno o en el mil”, explica Roberto Alcover, matemático y miembro del equipo de desarrollo de magiquo.
Una imagen es una matriz de píxeles dispuestos en filas y columnas. La red convolucional ayuda al ordenador a detectarla como si se tratara de un ojo humano. Para hacerlo preciso y que sea capaz de identificar objetos, cualesquiera que sean, estén donde estén en la imagen y se encuentren repetidos o no (y lo que es mejor sea capaz de encontrarlos de nuevo entre mil y una fotos), utiliza varios perceptrones. Es decir, varias neuronas o algoritmos artificiales, previamente programados, que van “recorriendo” la imagen inicial buscando la información que le interesa. Por ejemplo, un perceptrón buscará bordes y los “leerá de izquierda a derecha y de arriba abajo, pixel a pixel. Otro se encargará del color, otro del matiz… así irán superponiendo información de la imagen por capas. Cuando reúne ciertas características que se repiten para un objeto, asociará siempre esa información a ese objeto. En nuestro caso, una flor. “Cada una de las matrices que diseñas hace una cosa. Al final lo que tienes es una base con un montón de capas convolucionales. Con esas entidades reconoce lo que ha visto. Esta última capa sí que es densa y sirve para clasificar el objeto en el espacio, independientemente de donde esté”, afirma Alcover.

En flor_0.png tenemos la flor original sobre la que vamos a trabajar.
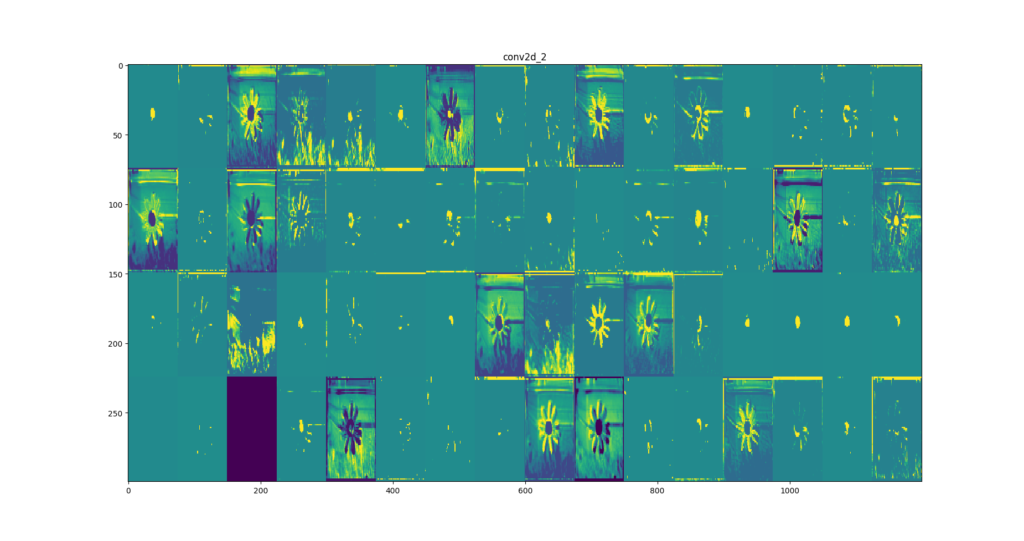
Hemos impreso el resultado obtenido tras aplicar cada una de las convoluciones a dicha imagen.
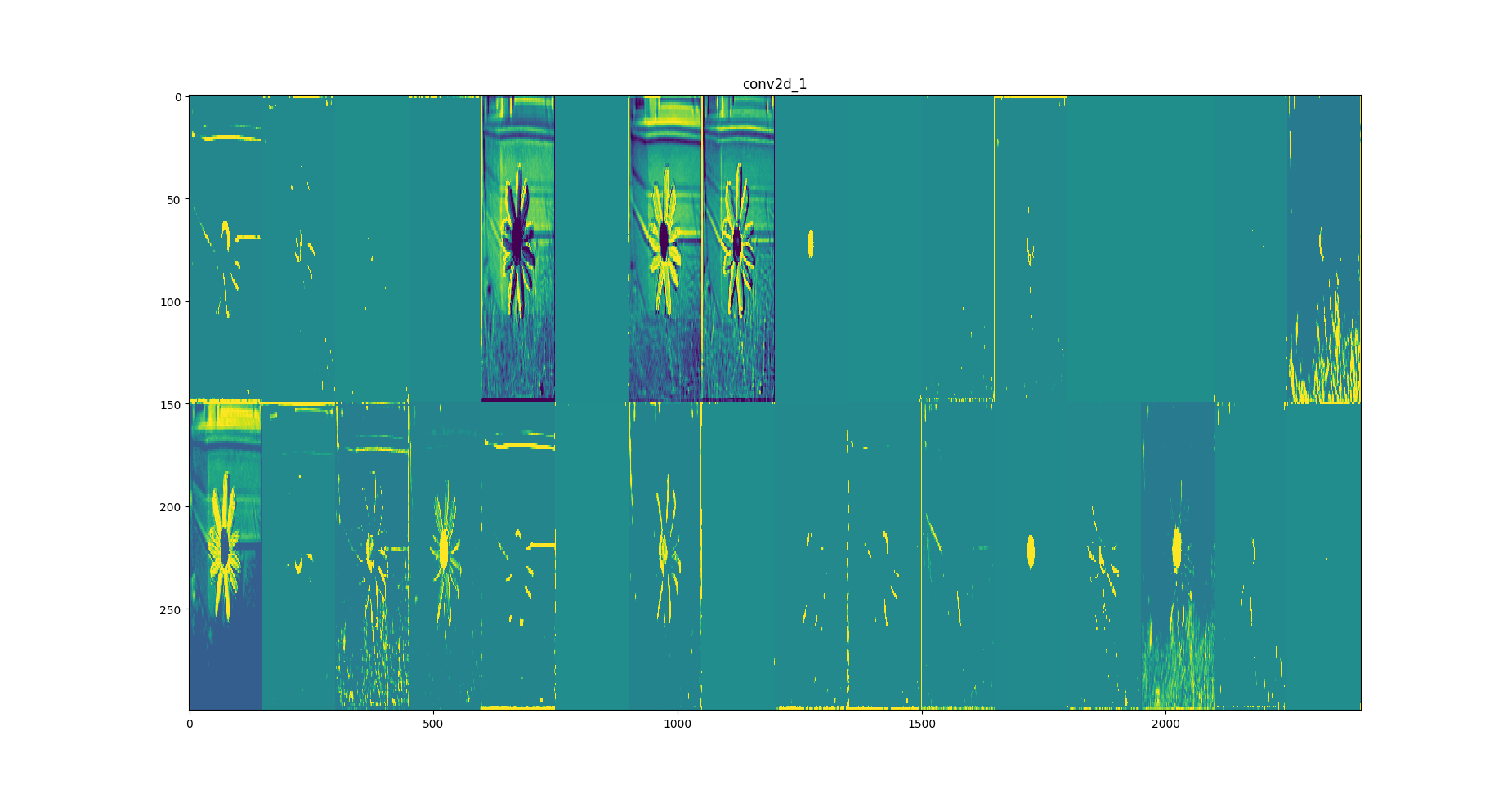
La imagen Conv1.png es el resultado tras aplicar la primera convolución a la imagen inicial. “En esta imagen, todo lo que sale resaltado en color amarillo es lo que nuestra red observa en la foto, por ejemplo, en esta primera convolución lo que está obteniendo son los bordes simples, verticales y horizontales, de las imágenes que le pasamos. Aquí obtenemos un total de 32 imágenes, 16 por fila, en la primera de ella vemos que está resaltando los bordes de los pétalos de la flor y su rama, mientras que en la decimosexta imagen (la última de la primera fila) lo que resalta es el césped de la imagen. En otras imágenes se puede ver resaltado el círculo de dentro de la flor. Así va aprendiendo cómo reconocer esa flor.”, explica Gemma Merlo, informática de magiquo y programadora de esta red convolucional.
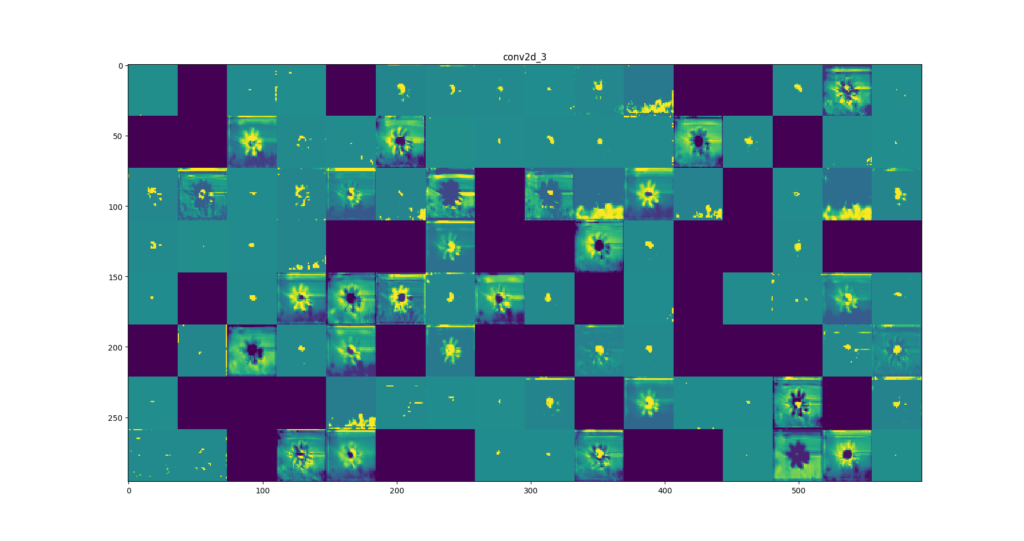
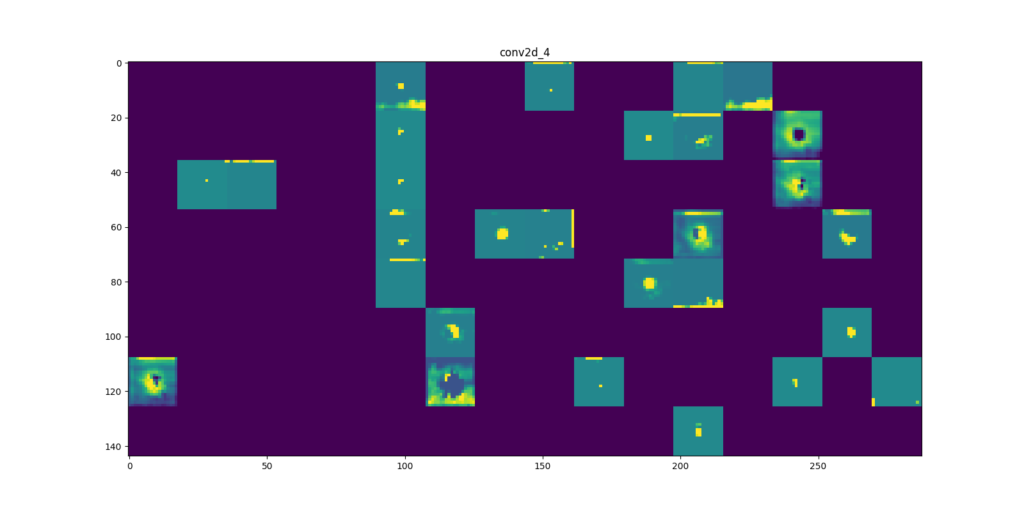
Gradiente
En heatmap.png hemos representado la visualización de las imágenes por gradiente. Coloreando un mapa de calor en la imagen sobre las partes de la flor original (flor_0.png) que hacen que nuestra red reconozca que se trata de una margarita. En este caso, vemos que en lo que se centra nuestra red convolucional para reconocer las margaritas es el círculo del centro de la flor y los pétalos, ya que es sobre esas partes donde se dibuja el mapa de calor.